
在上一期深度文章中,我们分析了谷歌是最具有潜力超越英伟达5万亿美元市值的公司,随后谷歌利好不断,巴菲特入股,发布天花板级别的AI模型
就在外界普遍预期“英伟达占据主导地位”的格局短期难以撼动时,谷歌连落两项关键合作,再次让行业把关注点转向它的算力布局:
正与 Meta 洽谈数十亿美元级的 TPU 采购,Meta 正考虑自 2027 年起,将部分推理算力从英伟达迁移至 Google TPU。
与 Anthropic 确立“最高百万颗 TPU”的扩容计划,规模直指数百亿美元;
要知道,Meta 是英伟达最大的客户之一。谷歌云内部的高管明确表示:
“若 TPU 采用率持续扩大,我们有能力从英伟达手中夺走约 10% 的年收入份额。”

换句话说——谷歌正在从 “模型 + 云” 两端同时发力,正面冲击英伟达的芯片帝国。一条全新的 “谷歌链” 正在快速成形,硅谷的 AI 供应链版图随时可能被彻底改写。
那么,最关键的问题来了:
当价值数百亿美元的算力订单开始流向谷歌,这是不是在宣告——英伟达这两年的芯片暴利时代,正在走向拐点?
谷歌 TPU 明明单卡性能不如英伟达,为什么却能靠“系统级性价比”一口气撬走 Meta、Anthropic这些巨头?
一旦资金开始撤离“英伟达链”,那条正在成形的万亿级“谷歌链”里,除了谷歌,谁最有机会成为下一只被资金疯抢的超级强势股?
面对“英伟达链 VS 谷歌链”,投资者的资金到底该怎么配置,才能吃到这波万亿级产业扩张的红利?
谷歌TPU凭何成为大模型公司的新选择?
理解谷歌为什么能突然撬动整个算力市场,我们得先看清一个大前提:英伟达在“单芯片性能”和“整柜峰值算力”上的统治力,从头到尾就没被撼动过。
Blackwell 架构这代产品,尤其是 B200 / GB200,训练猛、推理快、能效高,一个整柜 GB200 NVL72 能做到 1.4 EFLOPS ——这就是专门给“万亿参数模型”造的核武器。
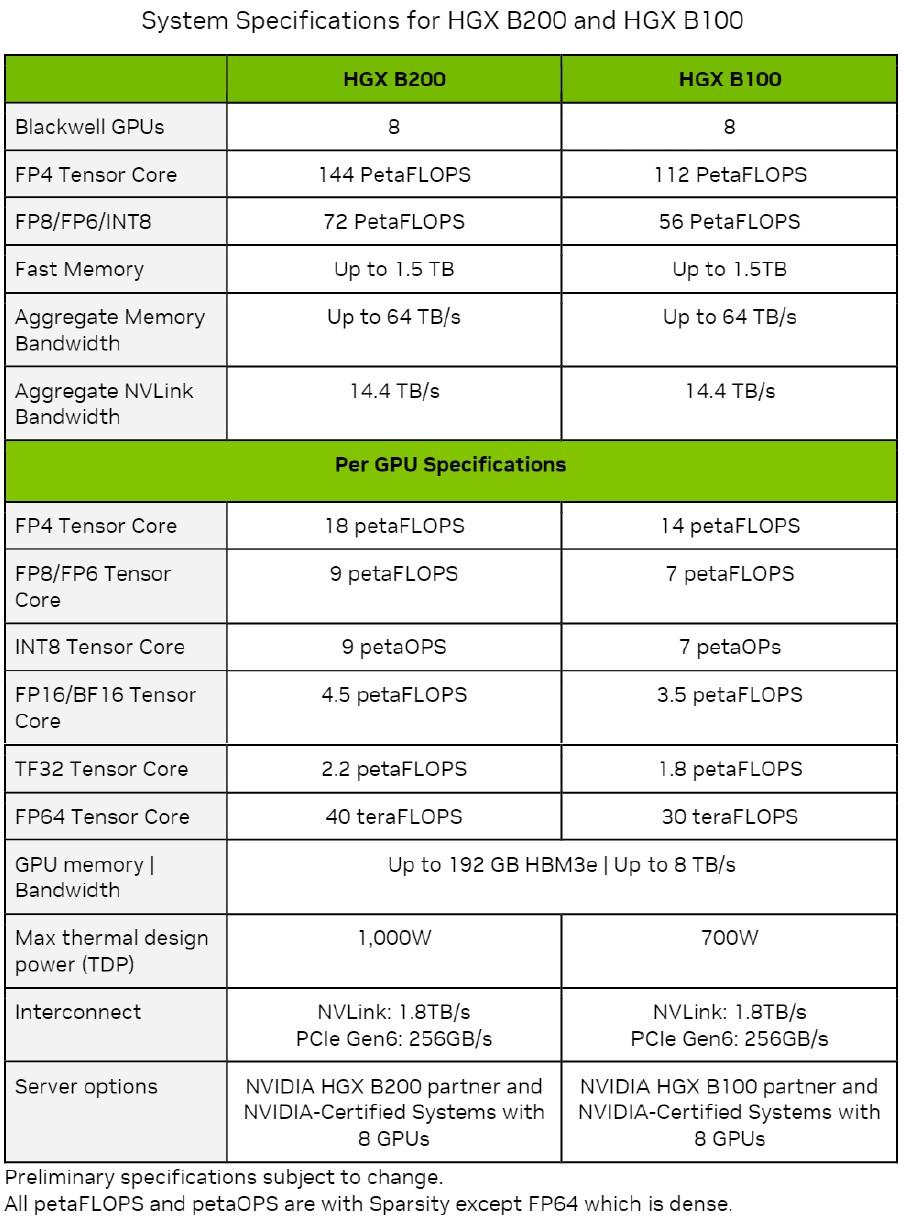
所以,只要讨论“单卡性能”和“极限峰值”,英伟达永远是行业标杆,这是行业公认的事实。
但也正因为如此,谷歌根本没有打算在英伟达最擅长的主场硬碰硬。谷歌选择的是另外一条路:不拼最强单卡,而是拼 规模、效率、成本、稳定性。谷歌要做的不是 GPU 的替代品,而是一整套系统级的算力平台。
这点从 TPU 的演进就看得很清楚。
第六代 TPU Trillium 旨在大幅降低训练成本。谷歌云测算,在训练 Llama2、Llama3 等主流大模型时,其“性能 / 成本比”比上一代最高提升约 2.1 倍。这意味着同样的预算可训练两倍规模的模型。更重要的是,Trillium 的分布式扩展效率极高,成千上万颗芯片组成的集群依然能接近满载运行。
到了第七代 TPU Ironwood,谷歌干脆不再走“堆更多显卡”这条路,而是把几千颗 TPU 整合成“一台巨型超级计算机”。一个 Pod 最多塞进 9,216 颗 TPU,背后还有 1.77PB 的共享 HBM 内存,这已经不像服务器集群,更像一台把机房装进机柜里的电脑。
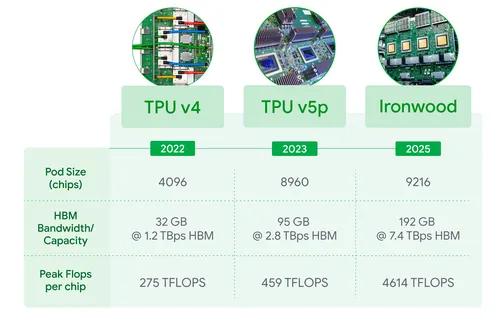
配合谷歌自研的光交换网络,把芯片间的通信延迟压到极低,超大模型在 Ironwood 上跑,不再需要在几千张卡之间来回搬数据——像在一台巨型电脑里跑一样顺滑,“内存墙”被直接跳过,推理速度自然更快。
如果先把那些复杂的技术参数暂时放一边,回到企业老板最在乎的一件事——这套算力三到五年总共要花多少钱也就是 TCO,总拥有成本),谷歌和英伟达之间的差别就一下子清楚了。
从谷歌自己的测试来看,在不少主流大模型任务上,TPU v5e / v6 在合适的负载下,性能 / 成本比相较传统高端 GPU 方案,往往可以做到 2–4 倍的提升。换句话说,同样的钱,你要么可以跑出几倍的产出,要么用更少的预算完成同样的训练。在实际业务里,很多公司的整体算力成本,保守看也能压下去 30%–40%,部分场景甚至可以做到更低。

用 谷歌云 的公开定价对比就更直观了:同一个地区,一颗 H100 的 Spot 价格是 2.25 美元/小时,而一颗 TPU v5e 只要 0.24 美元/小时。单芯片的计费价格,差 9 倍。
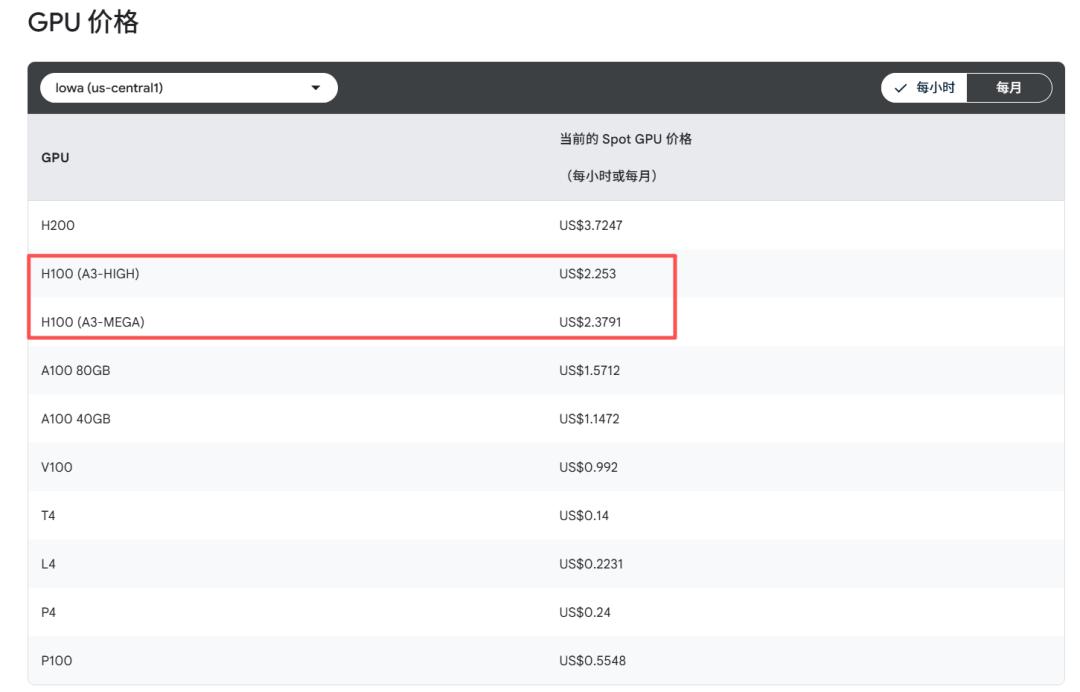
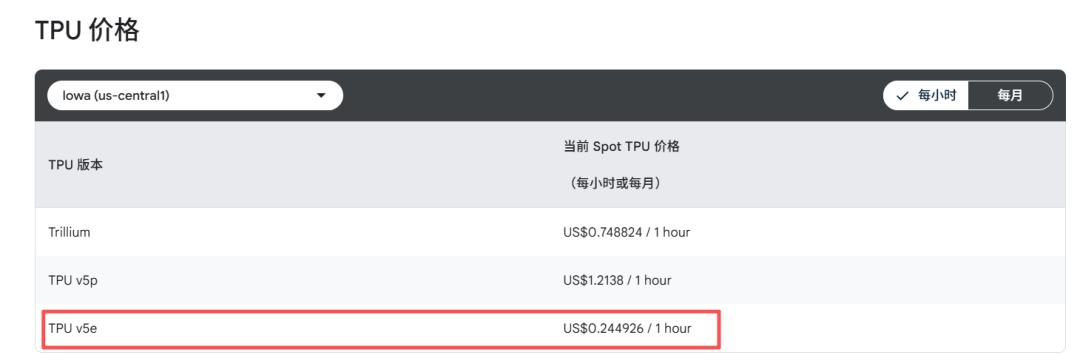
第三方测评也给出类似结论:在 GPT 这种规模的大模型训练上,TPU v5e 在保持差不多吞吐的前提下,总成本能做到高端 GPU 的“零头”级别。
正因为谷歌便宜、能扩容、集群效率高,大模型公司开始重新调整算力结构,这不是“为了省一点钱”,而是TSO(规模 × 成本 × 风险)的商业决策。
以 Anthropic 为例,他们之所以愿意把未来几年的核心算力交给谷歌,很简单:TPU 能用更低的预算撑起更大的模型规模。而且,把数据中心的建设和维护全部托付给 谷歌云,意味着他们不用像 OpenAI 或 xAI 那样,动辄投入数百亿美元去造机房、拉光纤、配电力。他们可以把全部精力集中在模型本身,这对一家创业公司来说是更务实的选择。

Meta 的出发点则不同,它更像是在做“风险对冲”。作为规模巨大的 AI 用户,仅依赖英伟达已经难以满足它未来的长期规划。把部分推理任务分配给 TPU,一方面让供应链更加稳健,另一方面也能在长期运营成本上做优化——特别是推理和微调这种每天都要消耗大量算力的场景,迁到更便宜的平台,节省的就是持续性的真实现金流。

当我们把所有信息拼到一起,其实逻辑非常清晰:它要比的是系统效率、总成本、长期稳定性。对大模型公司来说,这比单卡性能重要得多,因为企业最终要看的是:钱能省多少、扩容能不能稳定、未来能不能不被卡脖子。
更关键的是,美股投资网获悉,谷歌已经把 TPU 带进了高频交易公司、银行、国防部门 这些安全要求最严格的场景。能够在这些体系中本地落地,并通过最严苛的安全审查,这就意味着 TPU 已经跨过了 GPU 长期难以跨越的门槛:数据隔离、超低延迟、可审计性和主权安全。
这是一个质变。因为一旦金融和Z府系统开始用 TPU,影响的就不只是几张采购单,而是长期的 算力主权布局。
这等于首次打开了一块过去几乎由 GPU 垄断、并对外封闭的高价值市场。
行业格局随之出现结构性松动,一条全新的“谷歌链”正在快速成形。
谷歌AI芯片利好哪些公司
这不是简单的“换一家买硬件”,而是需求端的顶级巨头亲自推动的一次算力体系重排,对投资者来说含金量极高。那么,“谷歌链”到底由哪些核心环节组成?哪些公司最先受益?
第一个就是AVGO。很多人可能不知道,谷歌的 TPU 并不是它自己从头做到尾的,真正让 TPU 能“连得起来、跑得稳定、扩得下去”的核心通信和网络部分,几乎都是 AVGO 在提供。双方合作已经接近十年,绑定程度远比外界以为的深。
AVGO 在谷歌体系里最重要的三块能力,就是高速 SerDes、交换 ASIC,以及支撑谷歌 Jupiter 光网络的光交换芯片。它们分别就像 TPU 集群的“血管”“神经系统”和“主干公路”。没有这些东西,TPU 根本搭不出超大规模集群,谷歌的光网络也不可能做到现在这种体量。所以只要谷歌继续走专用加速器路线,AVGO 就是绕不过去的底层核心。
那 AVGO能在关键能力上抗衡英伟达吗?
答案是肯定的。英伟达之所以强,是因为它手里有 GPU、CUDA 和 NVLink 这三张王牌,尤其是 NVLink,这条自研高速互联从 2016 年一路迭代到 4.0,速度几乎是 PCIe Gen5 的三倍,是英伟达大集群性能的核心来源。
但别忘了,AVGO 本来就是做网络通信起家的,它在交换芯片、光通信和数据中心互联这些底层技术上积累深厚,完全具备和 NVLink 对抗的实力。简单来说,一边是“英伟达的私有高速通道”,另一边是“AVGO 的行业顶级网络架构”。在云和数据中心这种超大规模场景里,AVGO 的地位一点不弱。
这也是为什么我们在 2025 年初就提前明确推介 AVGO。

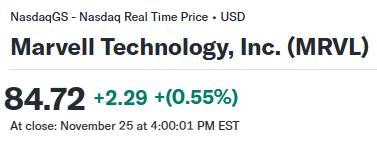
ASIC的代表玩家博通和Marvell(两家占ASIC市场超60%的份额),已经领先市场几个身位。前者作为谷歌自研AI芯片TPU的制造商,已维持合作关系将近10年之久,MRVL自推出该业务25年以来,已设计超过2000款ASIC,曾受亚马逊、谷歌、微软邀请开发定制AI芯片。
制造端由 台积电 TSM(TSM)、Amkor(AMKR) 与 日月光 ASE(ASX) 组成铁三角。TPU v7 对 3nm/2nm 制程、HBM 堆叠、高密度 Chiplet 封装的依赖进一步增强,TSMC 决定算力上限,AMKR 和 ASX 决定带宽能否落地。随着机构预期 2026 年谷歌 TPU 将成为全球最主要的自研 ASIC,这三家公司是算力迭代的硬核基础。
当芯片从晶圆厂走出,真正把 TPU 部署成“能用”的系统的是 Jabil(JBL)、Flex(FLEX) 与同样是我们2025必买公司的Celestica(CLS)。它们负责 TPU 模组、服务器机架、电源系统与整柜装配,是谷歌数据中心扩容最敏感、最直观的环节。随着 TPU v7 功耗与密度不断上升,机架结构、布线方式、散热设计都要全面重写,这三家整机 ODM 的单柜价值量与出货节奏随之提升,成为追踪谷歌 CapEx 的最佳风向标。
而系统的规模化运行,依赖于更高速的互联能力。谷歌的 Jupiter 光交换体系需要更高带宽的光模块,这是 Lumentum(LITE)、Coherent(COHR)以及 AVGO 的光通信业务 所擅长的领域。数据中心互联从 400G 升级到 800G、1.6T,这些厂商会最先感受到需求的跃升。没有高速光通信,就无法支撑 TPU 集群的横向扩张。
OCS(光电路交换机)上游也首次出现具备投资价值的美股公司。
谷歌采用的 Palomar OCS 依赖 2D MEMS 微镜阵列,这类高精度器件 ASP 高、工艺壁垒强,最直接的受益者包括 SiTime(SITM) 与 Luna Innovations(LUNA)。
同时,OCS 推动的高密度光路也带动了 IPG Photonics(IPGP)、Coherent(COHR) 等精密光学厂商在准直器、透镜阵列与硅光波导上的新增需求。这个环节在传统数据中心从未存在,是 OCS 打开的全新美股增量市场。
随着集群规模扩大,基础设施压力同步上升。能否解决高功耗带来的散热、电力与液冷需求,决定了数据中心是否能继续扩容。因此,VRT 成为谷歌链中最“通吃”的公司。无论是部署 GPU 还是 TPU,只要算力密度继续走高,VRT 的电源管理与液冷系统就是不可替代的底层能力。
最后,谷歌的 AI 战略并未停留在云端。为了让 Gemini Nano 在全球终端设备上本地运行,谷歌必须依赖高通(QCOM)提供的端侧算力平台。Snapdragon 的 NPU、DSP 和本地推理能力,是安卓生态能否真正跑起“端侧大模型”的关键基础。因此,谷歌的 AI 想真正触达普通用户,高通就是那个承上启下的核心一环。
当云端由 TPU 撑起、端侧由高通承载,谷歌的 AI 版图才真正被补全——这也意味着,谷歌正在从“云—端”两侧同时发力,构建一条完整、闭环、可规模化的算力体系。
而正是这条“云端 + 端侧”的双引擎,使整个行业发生了更深层的变化:AI 的算力版图,已经不再只靠单一供应商支撑。
AI 算力不再只有一条命脉!
站在更高的产业视角来看,谷歌 TPU 的崛起,触发的根本就不是“谁取代谁”的零和游戏,而是一次全球 AI 算力结构的“大扩容”!
过去两年,全球 AI 产业对英伟达的依赖度实在太高、太集中了!英伟达一旦有点风吹草动——产能紧张、交付延迟,或者价格波动——整个行业都得跟着心惊胆战,引发连锁反应!TPU 的大规模杀入市场,本质上是在给全球 AI 产业开辟第二条成熟、可靠的算力供给线!
这带来的影响,可不是仅仅“多了一个选择”那么简单!它让大模型公司、云厂商和所有企业用户第一次能够像在餐厅点菜一样,对算力进行组合式、精细化的配置:
稳定、重复的工作:直接交给 ASIC(专用芯片)。
需要灵活、高通用性的大模型:继续放在 GPU(英伟达阵营)。
对成本敏感、需要极致性价比的任务:用 TPU 做深度优化。
超高安全要求的场景:就采用本地化部署。
这意味着,AI 的底层基础设施正在从过去“英伟达说了算”的单一生态,彻底升级为“客户说了算”的“多层次算力池”!算力不再是单一的商品,而是变成了一个可组合、可调度、可精分的资源体系!
这种结构性变化,直接影响了资本市场对两条链条的估值逻辑:
英伟达链:看生态、看通用性、看平台溢价,是“成熟期的估值体系”。
谷歌链:看订单、看产能、看扩张速度,是“成长期的加速度逻辑”。
这不是两条供应链互相替代,而是全球 AI 基建第一次拥有了 更均衡、更弹性、更具扩展空间的双轨结构:
英伟达推高天花板——让模型变得更强;
谷歌 拓宽高速路——让算力供给更可持续、更规模化。
事实上,每一次有公司展示更高效的训练网络(无论是 GPU 还是 TPU),都会进一步加强市场对“AI 继续扩张”的信心循环。Google 这次的突破,不是 GPU 的终章,而是下一轮 算力投资的开场信号。因为越多公司加入 AI 军备竞赛,越多训练管线被打开,全球对 GPU 的需求反而会更强——所有追赶者都需要更多 GPU 才能缩短差距。
AI 赛道最终不是“谁的芯片更省电”的比赛,而是“谁能让算力更快扩张”的比赛。在这条扩张曲线上,英伟达仍然是目前唯一能够让全球快速“放大算力”的基础设施提供者。
因此,谷歌链的爆发不是在稀释英伟达,而是在为未来 3~5 年万亿级算力扩张铺设更安全、更立体、更可持续的双轨基建。两条链不是对立,而是共同驱动下一轮超大周期的发动机。


