
在ASIC市场,近日听到的一些言论是相悖的。
“全球众多ASIC项目中,90%会失败”这句话来自英伟达CEO黄仁勋。
黄仁勋对于 ASIC 的评价并不算多。因此相关言论一出,市场上关于 ASIC 成长性的讨论瞬间多了起来,各种猜测层出不穷。
黄仁勋表示,相较于英伟达主打通用GPU架构,ASIC专为特定任务打造,虽在单一用途上效能与效率极高,但缺乏灵活性与扩展性。这种“单点优化”策略,难以应对AI应用快速演进的现实。黄仁勋评价ASIC时并非否认其价值,而是强调“入场门槛与运维难度都很高”。他以谷歌TPU为例称,其团队是“全球最强ASIC团队”,但即便如此,谷歌Gemini模型仍同时部署在英伟达GPU上。
但市场上另一种声音同样有依据——在 ASIC 的迅猛发展中,英伟达已嗅到危险的信号。
ASIC,赶超GPU?
在算力芯片市场,ASIC的“簇拥者”可并不算少。在ASIC芯片大厂、云巨头等助推下,AI算力市场正在迎来新的临界点。
根据野村证券的最新报告,目前英伟达GPU占 AI 服务器市场 80% 以上,ASIC 仅占 8%-11%。
然而,从出货量的角度来看,情况正在发生变化。到2025 年,谷歌的 TPU 出货量预计将达到 150-200 万台,亚马逊 AWS Trainium 2 ASIC 约为 140-150 万台,而英伟达的 AI GPU 供应量将超过 500-600 万台。
供应链调查显示,Google 和 AWS 的 AI TPU/ASIC 的总出货量已经达到 Nvidia AI GPU 出货量的 40%-60%。
随着Meta 于 2026 年开始大规模部署其自主开发的 ASIC 解决方案,Microsoft 将于 2027 年开始大规模部署,预计ASIC 总出货量将在 2026 年的某个时候超过英伟达 GPU 出货量。
这也意味着,属于ASIC的时代将正式到来。
OpenAI宣布测试谷歌TPU的消息也进一步点燃市场热情。据悉,人工智能(AI)技术大厂OpenAI 已开始租用谷歌的AI芯片,以支持旗下ChatGPT 和其他产品的计算需求。对此OpenAI回应称,目前没有使用谷歌自研芯片来驱动产品的计划。
不过,OpenAI 发言人指出,虽然公司的AI 实验室确实正在初步测试部分谷歌的TPU,但目前尚无计划大规模采用。
目前,OpenAI 主要依赖英伟达的GPU以及AMD 的AI 芯片来满足其日益成长的AI计算需求。为了降低对于英伟达、AMD的依赖,OpenAI 也正在开发自家芯片,计划今年达成“tape-out”里程碑,即芯片设计完成并送交制造。
上一位采用谷歌TPU而引起轰动的是苹果。去年7月,苹果在官网的一篇论文中披露,其训练模型采用了谷歌研发的第四代AI ASIC芯片TPUv4和更新一代的芯片TPUv5。
在去年之前,与英伟达GPU相比,谷歌的 TPU还像是一位“名不见经传”的小将,如今看来,似乎已有实力与英伟达GPU展开一番较量。
但是在笔者看来,“ASIC芯片是否在未来有望碾压GPU?”这更像一个伪命题。
ASIC,核心优势
市场普遍认为,ASIC 芯片正成为 AI 芯片的重要分支。但是ASIC究竟以何种优势给GPU带来冲击?以及具体带来哪些冲击,相关讨论却较少。
针对一系列问题,笔者将对此展开讨论。
根据承担任务的不同,AI芯片主要可以分为两类,它们分别是AI训练芯片和AI推理芯片。
2025年,全球AI推理算力需求呈现爆发式增长,特别是在端侧应用场景中。这对于ASIC来说,也是一个契机。
首先说一下什么是推理。
推理是“用已训练好的模型处理数据” 的过程(比如用训练好的图像识别模型识别照片、用语音模型转写语音)。一旦模型部署,其算法逻辑(如 CNN 的卷积层、Transformer 的注意力机制)、计算流程(输入输出格式、精度需求)会长期固定,几乎不需要调整。
这种“固定性” 正好匹配 ASIC 的核心优势 ——为单一任务定制硬件架构:可以直接将推理算法的计算逻辑、数据路径“固化” 到芯片中,去掉所有无关的通用计算单元(如 GPU 中用于训练的动态调度模块、通用内存控制器),让硬件资源 100% 服务于推理计算。
同理,ASIC在训练任务中的能力就相对弱一点。因为训练任务算法迭代快,需求灵活。ASIC 若用于训练,算法更新时,芯片面临失效风险,性价比要低得多。
推理场景对“能效比”(每瓦功耗能提供的算力)和 “成本” 的敏感度远高于训练,而 ASIC 在这两方面具有碾压性优势。
能效比方面,谷歌TPU v5e TPU的能效比是英伟达H100 的 3 倍。
成本方面,AWS的Trainium 2 在推理任务中性价比比 H100 高 30%-40%,谷歌的TPUv5、亚马逊的 Trainium2 单位算力成本仅为英伟达 H100 的 70% 和 60%。
一个大模型可能只需要几十到几百张训练芯片(如 GPU),但推理阶段可能需要数万甚至数十万张芯片(比如 ChatGPT 的推理集群规模是训练集群的 10 倍以上)。因此ASIC 的 “定制化” 设计可以降低单芯片成本。
VerifiedMarketResearch数据显示,2023年AI推理芯片市场规模为158亿美元,预计到2030年将达到906亿美元,在2024-2030年预测期内的复合年增长率为22.6%。
当前的推理场景正呈现ASIC 与 GPU 共存竞争的格局,ASIC芯片市场空间巨大。
近日,博通CEO Hock Tan与CFO Kirsten Spears也在会议中强调,该公司AI推理领域的订单显著增加,该公司目前正与四个潜在的AI XPU客户紧密合作,计划在今年为摩根大通认为的Arm/软银和OpenAI等主要客户完成第一代AI XPU产品的流片。
再看训练市场的竞争态势。AI训练芯片市场,几乎没有几家竞争者,英伟达一家就占据了 AI 训练市场 90% 以上份额,其 Blackwell 架构支持 1.8 万亿参数模型训练,且 NVLink 6 技术实现 72 卡集群无缝互联。
上文提到,训练任务的“灵活性” 与 GPU 架构天然契合,此外,英伟达通过CUDA 平台构建了难以撼动的软件生态:90% 以上的 AI 框架(TensorFlow、PyTorch)原生支持 CUDA,开发者无需重写代码即可调用 GPU 算力。这种生态惯性使得即使 AMD、华为等厂商推出性能接近的训练芯片,用户迁移成本依然极高。
有业内人士向半导体产业纵横表示,模型架构的稳定性是 ASIC 发挥价值的核心前提——模型稳定时,ASIC 的低成本、高效能优势能充分释放;模型快速迭代甚至出现革命性变革时,ASIC 容易因适配滞后而失效。
这也是为什么业内一些专家将ASIC市场规模爆发的节点指向2026年。ASIC 的设计周期长达 1-2 年,而 AI 模型迭代速度极快(如大模型从 GPT-3 到 GPT-4 仅用 1 年)。若 ASIC 设计时锚定的模型过时(如 Transformer 替代 CNN),芯片可能直接失效。
而如今随着大模型的发展,算法初步固化。再加上ASIC成本的持续下探,它也便有了更好展示自己的舞台。
至于ASIC是否会替代GPU?在笔者看来这个问题为时尚早。
短时间内看,ASIC 和 GPU 的竞争,本质是 “效率” 与 “灵活性” 的权衡,二者暂时并非互相替代关系。ASIC 在特定场景的优势,无法打破 GPU 的生态壁垒;而 GPU 的通用性,让它在复杂任务中难以被替代。未来,两者会借助混合架构(如 GPU + ASIC 加速卡)和异构计算(如 CUDA 与定制指令集协同),实现资源最优配置。
未来随着 AI 市场的发展,究竟需要何种芯片,尚难定论。
芯片龙头,纷纷切入ASIC
除了谷歌,国内外均有多家AI芯片公司选择拥抱ASIC。
Meta
Meta的核心算力负载来源于推荐系统场景,具备自研强调专用性的ASIC芯片的土壤。
Meta于2023年和2024年分别推出MTIA V1和MTIA V2芯片。此外,Meta还计划2026年推出MTIA V3芯片,预计将搭载高端HBM,与V1/V2芯片专注于广告与社交网络等特定任务不同,有望扩展应用至模型的训练与推理任务。
亚马逊AWS
AWS在AI芯片的布局主要包含推理芯片Inferentia和训练芯片Trainium两大系列。
自2020年以来,亚马逊发布了三代Trainium芯片。其中Trainium3性能或较上一代提升2倍,能效提升40%,搭载该芯片的UltraServers性能预计提升4倍。
微软
2023年11月,微软在Ignite技术大会上发布了首款自家研发的AI芯片Azure Maia 100,以及应用于云端软件服务的芯片Azure Cobalt。两款芯片将由台积电代工,采用5nm制程技术。
Cobalt是基于Arm架构的通用型芯片,具有128个核心,Maia 100是一款专为 Azure 云服务和 AI 工作负载设计的 ASIC 芯片,用于云端训练和推理的,晶体管数量达到1050亿个。这两款芯片将导入微软Azure数据中心,支持OpenAI、Copilot等服务。
下一代Maiav2的设计已确定,后端设计及量产交付由GUC负责。除深化与GUC的合作外,微软还引入美满电子共同参与Maiav2进阶版的设计开发,以强化自研芯片的技术布局,有效分散开发过程中的技术与供应链风险。
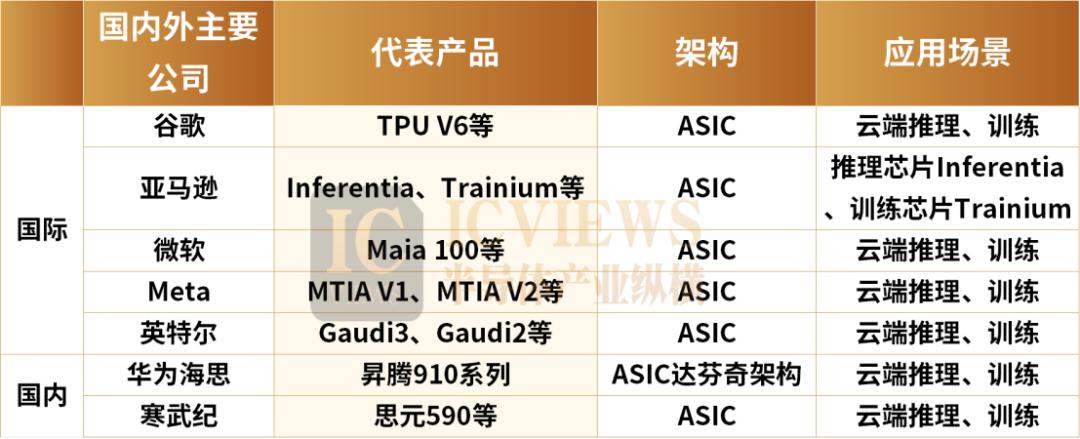
在国内ASIC芯片方面,华为和寒武纪表现突出。
华为海思旗下昇腾系列处理器自诞生以来,凭借其强劲的算力和创新的设计,特别是昇腾910B,在技术和应用上都取得了显著突破。
寒武纪作为国内AI芯片设计领域的佼佼者,在推理计算及边缘设备AI加速方面市场竞争力日益凸显。寒武纪的旗舰产品MLU590专注于AI训练与推理。
在全球 AI 芯片竞争中,国产 ASIC 芯片既面临挑战,也迎来历史性机遇。通过持续创新和技术突破,国产 ASIC 正逐步扩大市场份额。
ASIC芯片,两大受益者
在ASIC市场,目前博通以55%~60%的份额位居第一,Marvell以13%~15%的份额位列第二。
博通在AI芯片领域的核心优势在于定制化ASIC芯片和高速数据交换芯片,其解决方案广泛应用于数据中心、云计算、HPC(高性能计算)和5G基础设施等领域。博通的ASIC芯片业务已成为其核心增长点。财报披露,定制AI芯片(ASIC)销售额预计占第二季度总AI半导体收入的70%,达308亿美元(约合450亿美元)。
目前,博通已与三家超大规模云服务提供商(如谷歌、Meta、字节跳动)合作,并新增OpenAI、苹果等客户,未来计划扩展至七家大型科技企业。其中博通有两个大合作备受关注:第一是Meta与博通已合作开发了前两代AI训练加速处理器,目前双方正加速推进第三代MTIA芯片的研发,预计2024年下半年至2025年将取得重要进展。
Marvell的定制ASIC业务正成为其强劲增长的核心动力之一。Marvell的具体业务中,数据中心业务占据75%左右,属于高成长业务。这部分业务包括SSD 控制器、高端以太网交换机(Innovium)及定制 ASIC 业务(亚马逊 AWS 等定制化芯片),主要应用于云服务器、边缘计算等场景。
根据公司交流及产业链信息推测,Marvell 当前的 ASIC 收入主要来自亚马逊的 Trainium 2 和谷歌的 Axion Arm CPU 处理器,而公司与亚马逊合作的Inferential ASIC 项目也将在 2025 年(即 2026 财年)开始量产。公司与微软合作的 Microsoft Maia 项目,有望在 2026 年(即 2027 财年)。



